
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- the platform
- ngrok
- docker compose
- 영화 리뷰
- 로깅 서버
- django
- GNN
- ML/DL
- Heterogeneous Graphs
- Terragrunt
- KG embedding
- cs224w
- BigQuery
- IaaC
- argocd
- DevOps
- 2352
- SCP 재단
- 영화 추천
- GNNExplainer
- knowledge graph
- boj2352
- cloudsql
- Graph Neural Network
- auto reload
- Terraform
- RGCN
- npm7
- auto-reload
- SCP294
- Today
- Total
Itmom's blog
bigquery로 로깅 서버 구축 본문
1. Logging Server 요구사항
회사의 제품이 계속 다각도로 변하는 상황이다보니 같은 이벤트여도 schema가 바뀌기도 하고, 수집 가능한 유저 이벤트의 종류가 폭발적으로 증가하고 있다.
event의 종류는 계속 증가하는데, 이벤트의 스키마 정의를 담당해 정리해줄 인력이 없다보니 우선은 이벤트를 모아놓고 나중에 스키마를 변경하거나 데이터를 잘 가공해서 사용하자는 결론에 도달했다.
즉, 이벤트의 스키마가 변할 수도 있다는 조건과 이벤트의 스키마를 알아서 유추해주어야 한다는 조건이 붙었다.
당장의 데이터 양이 많지는 않은 만큼 분석을 쉽게 할 수 있도록 도와주는 데이터 웨어하우스인 빅쿼리에 데이터를 저장하기로 하였는데,
빅쿼리는 cloud storage와 달리 정형화된 데이터만을 저장할 수 있기에 이벤트의 스키마 유추가 반드시 필요하다.
2. 동적 스키마 유츄
{
"eventName": "apphome_start_typing_button_clicked",
"id": "blabla",
"email": "test@email.com",
"data": {}
}위와 같은 JSON 형태의 데이터를 frontend 쪽에서 api 형태로 전달받아 bigqeury에 저장하기 위해, 아래 코드와 같이 value의 type 값을 이용해 schema를 추측하여 생성하는 방식을 이용하였다.
추가적으로 일 단위 partitioning 기능을 추가하였다.
public checkOrCreateTable = async (
datasetId: string,
tableId: string,
data: JSON,
): Promise<void> => {
const storage: BigQuery = await this.storageService.get();
const table = storage.dataset(datasetId).table(tableId);
const tableExists = await table.exists();
if (!tableExists[0]) {
const schema = Object.keys(data).map(key => {
return getSchemaType(key);
});
const timePartitioning = {
type: "DAY",
};
const options = {
location: "US",
timePartitioning: timePartitioning,
schema: schema,
};
await table.create(options);
}
};생성된 테이블은 다음과 같다.
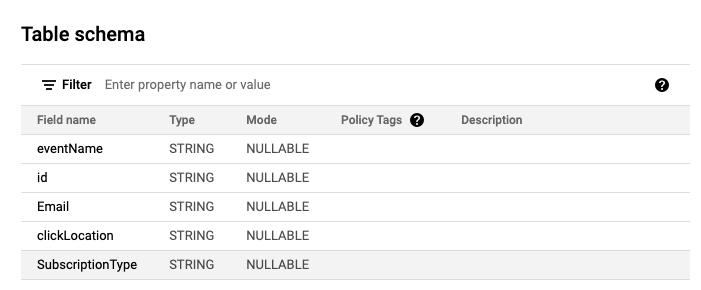
3. 스키마 변경
만약 같은 이벤트 이름을 가지고 있는 데이터임에도 다른 스키마를 가진 json 데이터가 input으로 주어진다면 PartialFailureError와 같은 에러가 발생하게 된다. 해당 상황에 대처를 해주기 위해 event data가 변경된 경우에 schema를 동적으로 변경해줄 필요가 있다. 다만, 누군가 악의적인 공격을 할 경우에 대비해 column deletion은 이루어지지 않고 기존 column에 새로운 column을 nullable하게 추가하는 방식을 사용하였다. 구현한 코드는 다음과 같다.
public updateTable = async (table: Table, data: JSON): Promise<void> => {
const [metadata] = await table.getMetadata();
const currSchema = metadata.schema.fields;
const currentKeys = currSchema.reduce((prev, curr) => {
return prev.add(curr.name);
}, new Set());
const editedSchema = Object.keys(data).reduce((prev, curr) => {
if (!currentKeys.has(curr)) {
prev.push(getSchemaType(curr));
}
return prev;
}, currSchema);
metadata.schema.fields = editedSchema;
await table.setMetadata(metadata);
};Error 없이 잘 작동한다! 햅삐~~ ㅎㅎ
'Development > Devops' 카테고리의 다른 글
| ArgoCD를 이용한 CD 시스템 구축 (0) | 2022.02.26 |
|---|---|
| Terragrunt - DRY and maintainable Terraform code (0) | 2022.02.17 |